


第一章、基础技术栈
1.1)集合,string等基础问题
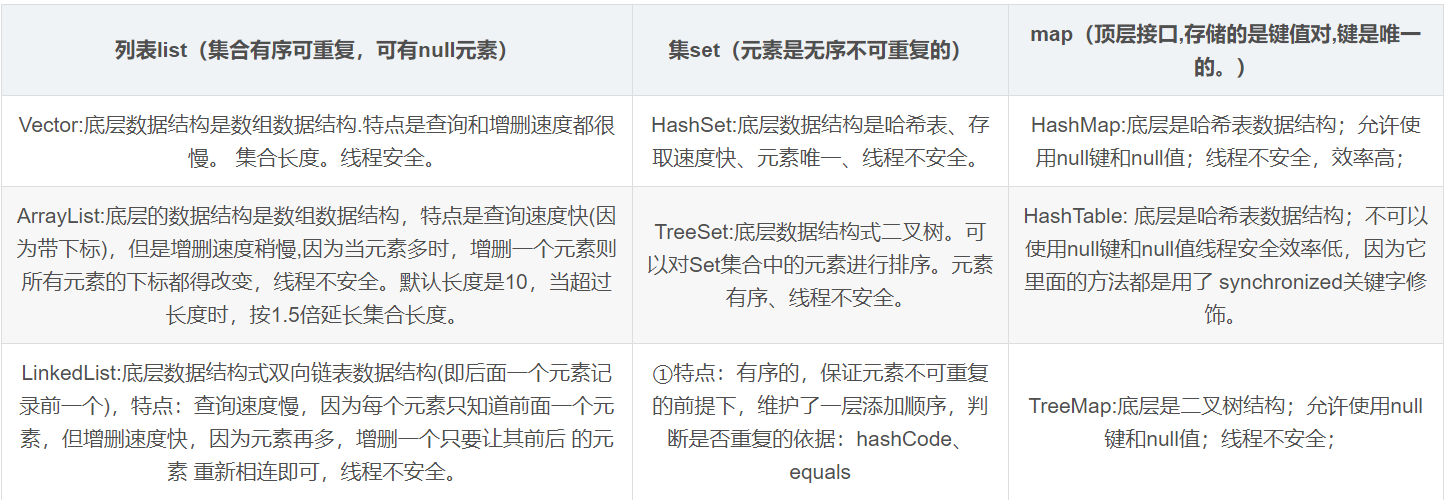
1、arraylist ,linkedlist的区别,为啥集合有的快有的慢
①ArrayList它的底层是数组,有下标的概念,可以通过index下标直接定位元素,所以查询快;在增删时,会进行扩容判断和拷贝,所以增删慢。
②LinkedList的底层是双向链表。每次查询都要循环遍历,所以查询慢;在增删时只需要链接新的元素,而不用修改列表中剩余的元素,所以增删快。
集合有的快有的慢,主要是因为它们的底层实现不同。
2、字符串倒叙输出
有很多种方法,最简单的就是使用StringBuilder类,它里面有个reverse()方法,可以将字符串进行倒序输出。
第二种是String类的toCharArray()方法把字符串转换为char数组。使用循环将数组中的字符进行倒序交换,输出结果。
2.1、字符串常用方法
toCharArray() 将字符串转换为字符数组
split(String regex) 切割
substring(int beginIndex, int endIndex)截取字串
int length() 获取字符串的长度
int indexOf(String str) 获取特定字符的位置
toUpperCase() 转大写转小写忽略大小写
2.2、字符串+号拼接的底层原理
看一段代码:
public class Test {
public static void main(String[] args) {
String a = "abc";
String b = "def";
String c = "abc" + "def";
String d = a + "def";
String e = new String("abc") + "abc";
String g = "abcdef";
}
}反编译后
public class Test
{
public Test()
{
}
public static void main(String args[])
{
String a = "abc";
String b = "def";
String c = "abcdef";
String d = (new StringBuilder()).append(a).append("def").toString();
String e = (new StringBuilder()).append(new String("abc")).append("abc").toString();
String g = "abcdef";
}
}结论:字符串+拼接如果无变量和new关键词参与则在字符串常量池。。
如果有变量或者是new关键词参与拼接, 那么就会都new出一个StringBuilder对象, 然后使用append方法, 随后又使用toString方法来new一个对应的String类, 这样繁琐的创建对象, 不仅消耗时间, 还会消耗内存资源。
所以:循环体内,字符串的连接方式,使用 StringBuilder 的 append 方法进行扩展。而不要使用+
3、讲一下Java的集合框架
说到集合框架我们可以把集合框架分为两个部分,单列集合collection和双列集合顶层接口 map。其中map的存储是key-value形式,collection下面有set接口特点是存储无序不可重复,list接口存储有序可重复。
4、定义线程安全的map,有哪些方法,ConcurrentHashMap原理
①定义线程安全的Map可以通过在每个方法上添加synchronized关键字实现或者使用Collections.synchronizedMap方法来保证线程安全。但是这样效率比较低。
②还可使用ConcurrentHashMap。原理是采用分段锁的机制,将整个Map分成多个Segment,在每个Segment上都加锁,不同的线程可以同时访问不同的Segment,这样兼顾了线程安全和运行效率。
5、equals与==
①==:如果比较的对象是基本数据类型,则比较的是数值;如果比较的是引用数据类型,则比较的是对象的地址值。
②equals():用来比较两个对象的内容是否相等。equals方法不能用于基本数据类型的变量,如果没有对equals方法进行重写,则比较的是对象的地址值。
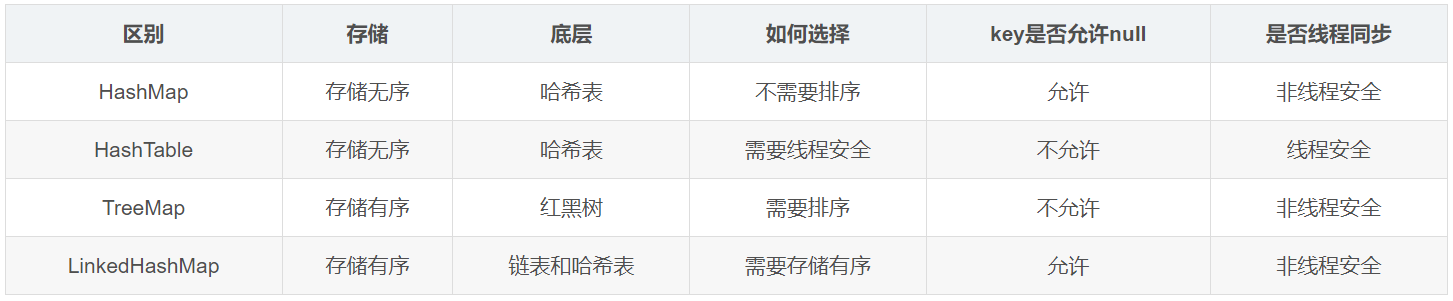
6、hashtable和hashmap的区别
hashmap底层是哈希表存储是无序的它和HashTable最大的区别是hashmap线程不安全并且key值允许为null,而HashTable线程安全并且key值不允许为null,由于Hashtable直接在put和get方法上面加synchronized关键字来实现线程安全所有操作都需要竞争同一把锁所以效率很低。
7.饿汉式单例设计模式的特点
#饿汉模式
public class Test1{
//1、私有化本类所有的构造方法
private Test1(){}
//2、直接在本类中创建唯一对象
private static Test1 t1 = new Test1();
//3、提供外界获取唯一对象的方法(公共的、静态的)
public static Test1 getInstance(){
return t1;
}
}
#懒汉模式
public class LazySingleton {
private static LazySingleton instance;
private LazySingleton() {}
public static LazySingleton getInstance() {
if (instance == null) {
instance = new LazySingleton();
}
return instance;
}
}
①懒汉式模式的特点是类加载时没有生成单例,只有当第一次调用 getlnstance (获取实例)方法 时才去创建这个单例。(比较懒别人喊一次才动一次?)。
②好处:不存在浪费内存的问题,弊端:在多线程环境下,可能不能保证对象是唯一的
public class Test2{
//1、私有化本类所有的构造方法
private Test2(){ }
//private和static修饰的成员变量
private static Test2 t2;
//3、提供外界获取唯一对象的方法(公共的、静态的)
public static Test2 getInstance(){
if(t2 == null){
//2、在本类中创建唯一对象
t2 = new Test2();
}
return t2;
}
}8、什么是哈希表
哈希表又叫散列表是一种数据结构,特点是查找增删都很快。哈希表里面每个数据都有唯一的键(key),把这个关键码值(key)通过映射函数映射到哈希表中一个位置来访问。
这个映射函数叫做哈希函数(散列函数),可以把任意长度的key值变换输出成固定长度的哈希值(Hash value)。一个好的哈希函数能够将键均匀地映射到哈希表中,以减少冲突和查找时间。
Hash code是一种编码方式,在Java中,每个对象都会有一个hashcode。Java可以通过这个hashcode来识别一个对象。
9、什么是哈希冲突,怎么解决
哈希函数把key变换输出为哈希码(哈希值),当不同的key值产生的哈希值H(key)是一样的,就产生了哈希冲突。
解决哈希冲突的方法
(1) 再哈希法
当发生冲突时,用不同的哈希函数计算地址,直到无冲突。虽然不易发生聚集,但是增加了计算时间。
(2) 链地址法
通过将具有相同哈希码的数据元素存储在一个链表中,来避免冲突的发生。
在查询、插入或删除数据元素时,首先根据哈希码找到对应的链表,然后在链表中搜索或修改相应的数据元素。
(3)建立公共溢出区
将哈希表分为基本表和溢出表两部分,将冲突的元素存储在另一个溢出表中
10、final关键字可以修饰哪些对象
final类:不可被继承,如java.lang.Math就是一个 final类,不可被继承。
final方法:不可被重写
final变量:final修饰的变量是一个常量一般和static联用。只能被赋值一次在初始化后不可改变变量值。如果final变量是引用变量,则不可以改变它的引用对象,但可以改变对象的属性。
public static final double pi=3.14;
11、lise集合便利查找其中的一项怎么处理比较快。
1. 普通 List(如 ArrayList、LinkedList)的顺序查找
ArrayList 基于数组实现,LinkedList 基于双向链表实现。对于它们来说,最基础的查找方式就是顺序遍历。
import java.util.ArrayList;
import java.util.List;
public class ListSearchExample {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(10);
list.add(20);
list.add(30);
list.add(40);
list.add(50);
int target = 30;
boolean found = false;
for (int i = 0; i < list.size(); i++) {
if (list.get(i).equals(target)) {
System.out.println("找到了元素 " + target + ",索引为 " + i);
found = true;
break;
}
}
if (!found) {
System.out.println("未找到元素 " + target);
}
}
}
复杂度分析:这种顺序查找方式的时间复杂度是 ,其中 是列表的长度。也就是说,随着列表元素数量的增加,查找所需的时间会线性增长。
2. 对有序 List 使用二分查找
如果 List 中的元素是有序排列的(比如按升序排列),可以使用二分查找来提高查找效率。
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class BinarySearchExample {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(10);
list.add(20);
list.add(30);
list.add(40);
list.add(50);
int target = 30;
int index = Collections.binarySearch(list, target);
if (index >= 0) {
System.out.println("找到了元素 " + target + ",索引为 " + index);
} else {
System.out.println("未找到元素 " + target);
}
}
}
3. 利用 Map 替代 List 进行查找
如果需要频繁进行查找操作,使用 Map 会更加高效。Map 基于哈希表实现,查找的时间复杂度接近 。
import java.util.HashMap;
import java.util.Map;
public class MapSearchExample {
public static void main(String[] args) {
Map<Integer, Integer> map = new HashMap<>();
map.put(10, 10);
map.put(20, 20);
map.put(30, 30);
map.put(40, 40);
map.put(50, 50);
int target = 30;
if (map.containsKey(target)) {
System.out.println("找到了元素 " + target);
} else {
System.out.println("未找到元素 " + target);
}
}
}这里 Map 的键就是要查找的元素,通过 containsKey 方法可以快速判断元素是否存在。
综上所述,若 List 无序,顺序查找是常规做法;若 List 有序,二分查找更高效;而当需要频繁查找时,使用 Map 是最佳选择。
12、固定的不可变的一些对象,放到哪里让全局都可以使用?
放在常量的类里,配置到数据库里,放在配置文件里,放到缓存里面,第三方配置中心
1.2)java8新特性,xxx原理。反射等高级问题
1、Java8有哪些新特性
Java8出现了很多新特性我说几个比较大的改变,
第一个是接口可以写默认方法和静态方法,默认方法用default修饰符标记,不强制实现类实现默认方法。
第二个是stream流,提供了便捷快速的操作数据的方式。
第三个是Lambda表达式和函数式接口,函数式接口仅有一个抽象方法的接口,Lambda 表达式本质上是一个匿名方法,让我们的代码更简洁直观。
第四个Java 8引入了重复注解的概念,允许在同一个地方多次使用同一个注解。
2、单例模式
1)饿汉式单例设计模式的特点
①饿汉式模式的特点是类一旦加载就创建一个单例,保证在调用 getInstance (获取实例)方法之前单例就已经存在了。(比较饿,没喊就迫不及待的创建了)。
②好处:就算在多线程环境下,也一定可以保证对象是唯一的。弊端:创建比较早,有浪费内存的现象。
2)懒汉式单例设计模式的特点
在第一次使用时才创建实例,但需要考虑线程安全问题。

评论区